Synthetic Data Generation using rendering engines is a time-consuming endeavor, with the biggest bottlenecks being creating the 3D scenes, as well as laying out the different elements of the scene as would be found in the target domain. The MetaSim [1] architecture introduced in 2021 (way back when I completed my MSc) uses a Graph Convolutional Network to learn the distribution of the target domain and modify the scene in the rendering engine accordingly, so that the generated data is as faithful as possible to the target domain it will be used in.
This short write-up summarizes my MSc thesis focusing on investigating how well the MetaSim architecture adapts to the Unity game engine and a different open source dataset focused on everyday objects, from the TYO-L dataset [2]. I discovered that while the architecture can work and succesfully modify the scene in Unity to match a target distribution, it remains a brittle method and requires extensive hyperparameter tuning. I use an adapted version of Kar et al. [1] code found here.
The meta-sim architecture
This architecture represents a 3D environment in a rendering engine as a graph. It uses a Graph Convolutional Network (GCN) to learn the graph structure, and then uses a 3D rendering engine to generate images from the graph. The architecture is trained using a Maximum Mean Discrepancy (MMD) loss, which is a measure of distance between two distributions.
The learning objective is generating images from a source distribution that are as close as possible to a target distribution, while using a standard rendering engine such as Unity
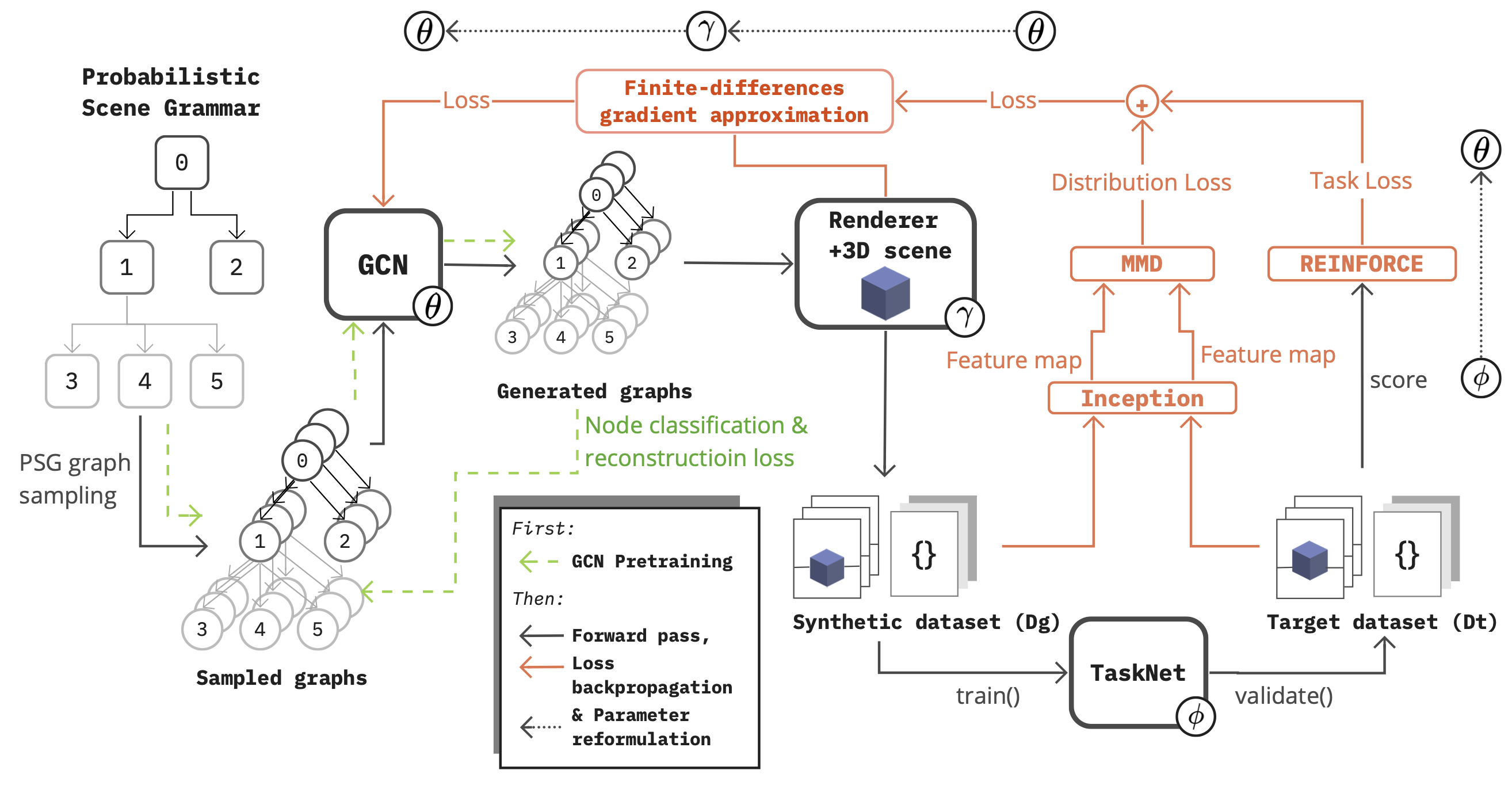
Meta-sim architecture diagram showing the GCN learning pipeline
We define multiple scene attributes that can be used to modify the scene. We also define a set of classes, the available objects in the scene, and the camera, lighting, background, scene and image. The latter are nodes in the scene, while the former are node poperties for the available objects.
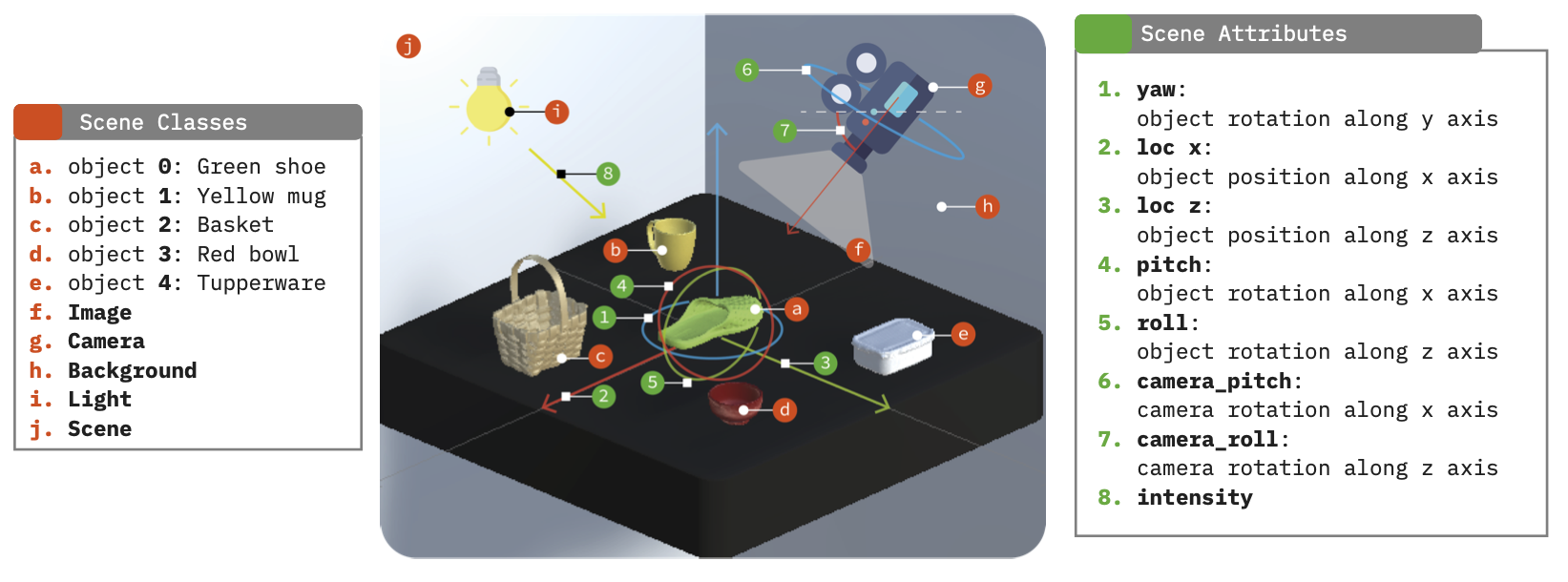
3D scene structure showing nodes and properties in Unity
Graph Convolutional Network autoencoder
The MetaSim architecture can be understood as a GCN autoencoder, we have an encoder GCN that learns the representation of the graph which represents the scene in the rendering engine, and a decoder which is able to generate graph representations of the scene that can then be used to lay out the scene in the rendering engine.
The encoder and decoder GCNs are identical, differing only in their output dimensions, and are defined below as a torch.nn.Module containing multiple GraphConvolution layers. A graph convolution updates a node's features by aggregating information from its neighbors in the graph, allowing the network to learn both the properties of individual objects and the relationships between them—essential for capturing the structure of a scene.
Encoder-decoder architecture:
Note: These models have been adapted from https://github.com/nv-tlabs/meta-sim.
Learning to rotate a single asset
During training, the architecture is learning to rotate a single object 90 degrees based on a target dataset whose distribution is centered around 90 degrees.
We can see the generated images:

Generated images showing rotation learning progress
And the mean of the generated distribution shifting towards the mean of the target distribution:
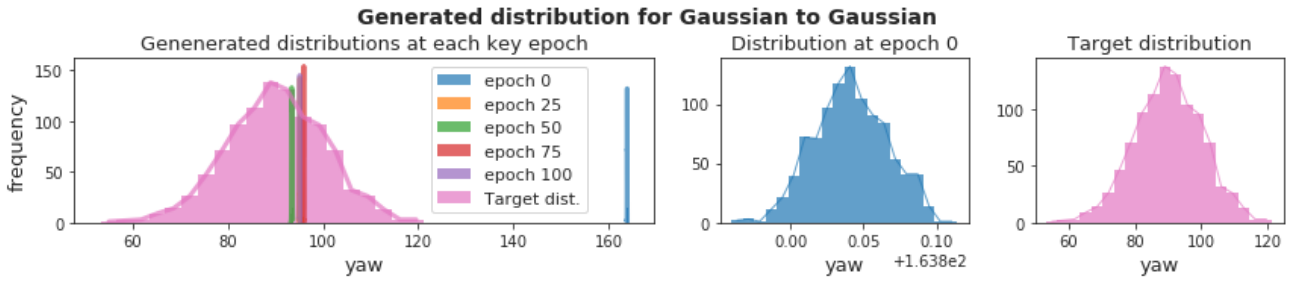
Yaw distribution convergence towards target distribution
Learning to pick and rotate the right asset from a pool of multiple assets
We extended the learning task to for the network to learn more degrees of freedom to match the target image. In this case, the network is learning to rotate and choose a single object from a pool of multiple ones to match the target
In the example below the network learns to select the right asset and rotate it to a 90 degree angle:

Network learning to select and rotate asset from multiple options
Learning to pick, rotate and move a single asset from a pool of multiple assets
We extended the learning task to for the network to learn more degrees of freedom to match the target image. In this case, the network is learning to rotate and move a single object from a pool of multiple ones.
In the example below, the network learns to select the right asset, and move it to the right position at the bottom right corner.

Network learning to select, rotate and position asset
Conclusions
My study demonstrates that while the MetaSim architecture can successfully generate synthetic data in Unity, it struggles with scalability and reproducibility. The learning process proved highly fragile when applied to a new 3D scene different from the original study—hyperparameters that worked in one setting rarely transferred to another.
Rendering speed and parallel processing are essential for practical training, but even with these in place, the architecture's sensitivity to configuration makes it difficult to deploy reliably across different domains. Future work addressing learning stability under complex settings could unlock the broader potential of GCN-based synthetic data generation.
[1] Kar, A., Prakash, A., Liu, M. Y., Cameracci, E., Yuan, J., Rusiniak, M., Acuna, D., Torralba, A., & Fidler, S. (2019). Meta-sim: Learning to generate synthetic datasets. Proceedings of the IEEE International Conference on Computer Vision, 2019-Octob, 4550–4559. https://doi.org/10.1109/ICCV.2019.00465
[2] Hodaň, T., Michel, F., Brachmann, E., Kehl, W., Buch, A. G., Kraft, D., Drost, B., Vidal, J., Ihrke, S., Zabulis, X., Sahin, C., Manhardt, F., Tombari, F., Kim, T. K., Matas, J., & Rother, C. (2018). BOP: Benchmark for 6D object pose estimation. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 11214 LNCS, 19–35. https://doi.org/10.1007/978-3-030-01249-6_2