This is an updated version of the blog I made years ago on generating synthetic data with Blender to fine-tune a YOLO model, if you're looking for that blog, you can find it here.
Synthetic data is a powerful tool to get Machine Learning practitioners off the ground fast into a working model that can perform the task sufficiently well, while saving resources on data annotation.
In this post I'll walk through a concrete object detection setup: generating training data with Blender via the sdg-engine package, fine-tuning a DEtection TRansformer (DETR) with HuggingFace 🤗 transformers and datasets, and evaluating on real-world data from the "BOP: Benchmark for 6D Object Pose Estimation" [1].
I'll use the "HomebrewedDB: RGB-D Dataset for 6D Pose Estimation of 3D Objects" [2] — specifically scene No. 3 — as both the visual reference for the synthetic scene and the source of labelled validation data, so I can measure how well the model generalizes from synthetic to real images directly on an open source dataset.

Sample from the Homebrew BOP dataset showing 4 different objects on a rotating platform
Introduction
The pipeline has two main phases: (1) preparing a real-world validation set and generating a synthetic training set in Blender, and (2) fine-tuning DETR on the synthetic dataset and evaluate it on the real-world dataset. Both datasets are stored as HuggingFace imagefolder datasets and pushed to the Hub for easy interoperability.
A more detailed, step-by-step tutorial is available in two parts: Part 1 — Generate data using Blender and Part 2 — Fine-tune DETR, this includes all code details for reproducibility.
Validation data and synthetic data generation
The Homebrew dataset provides real-world ground truth; without it we wouldn't be able to properly measure performance on the target domain. In order to make the dataset interoperable, I downloaded the BOP validation data and converted it into an imagefolder with COCO-style annotations (bounding boxes, categories, areas), then pushed it to the Hub as a private reposotory.
Then, to generate the training synthetic data, sdg-engine needs a Blender scene and a YAML config that describes how to sample it. The scene I use is a simple replica of the Homebrew setup (camera, lights, a few objects), which can be seen below.
Quick overview of the HB Blender scene
The config below drives resolution, visibility checks, and a parameter sweep (yaw, roll, camera height, etc.):
Finally, I generated the data with a single command; the output is an imagefolder that can be pushed to the Hub the same way as the validation set.
Tip: I refrained from spending too much time on photorealism here; improving the scene is one of the main levers for boosting the fine-tuned model later.
Fine-tuning DETR
With both datasets on the Hub, I loaded them and prepared an image_processor from the facebook/detr-resnet-50-dc5 checkpoint so that inputs match what the pretrained model expects.
Data augmentation is done with albumentations (horizontal flip, brightness/contrast, rotation, scale, blur, noise);
the validation set is only resized/padded to a fixed size so evaluation stays close to the real-world distribution. Transformations are applied to both images and bounding boxes so labels stay aligned.
Finally, with all of this in order, we can train the DetrForObjectDetection model from the transformers library. Evaluation uses TorchMetrics' Mean Average Precision (mAP) on the real world dataset; the progress of this training run is logged using Weights & Biases.
Results
This is the fun bit, here's where we can verify that our model is able to generalize from synthetic data to the real world task. From looking at the training loss we see a continuous decrease over the 10k steps. The curve is a bit jumpy; a smaller learning rate or batch size could smooth it, but learning is happening.
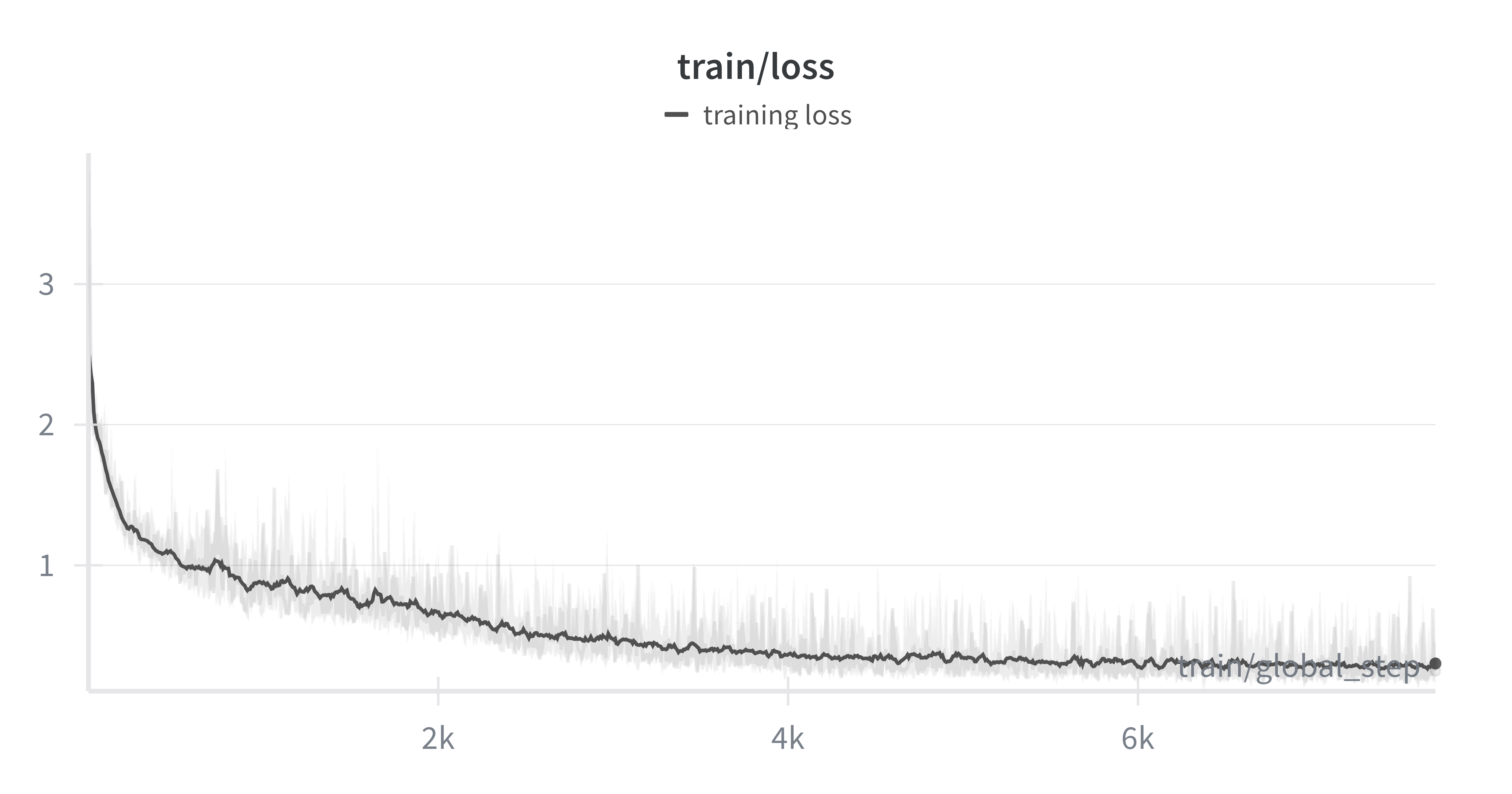
Fine-tuning loss curve showing steady decline over 10,000 steps
This is not enough to determine whether generalization is happening though. Inspecting the evaluation loss on the real-world validation set we also see a steady decrease, which indicates that the model is generalizing from synthetic to real data.
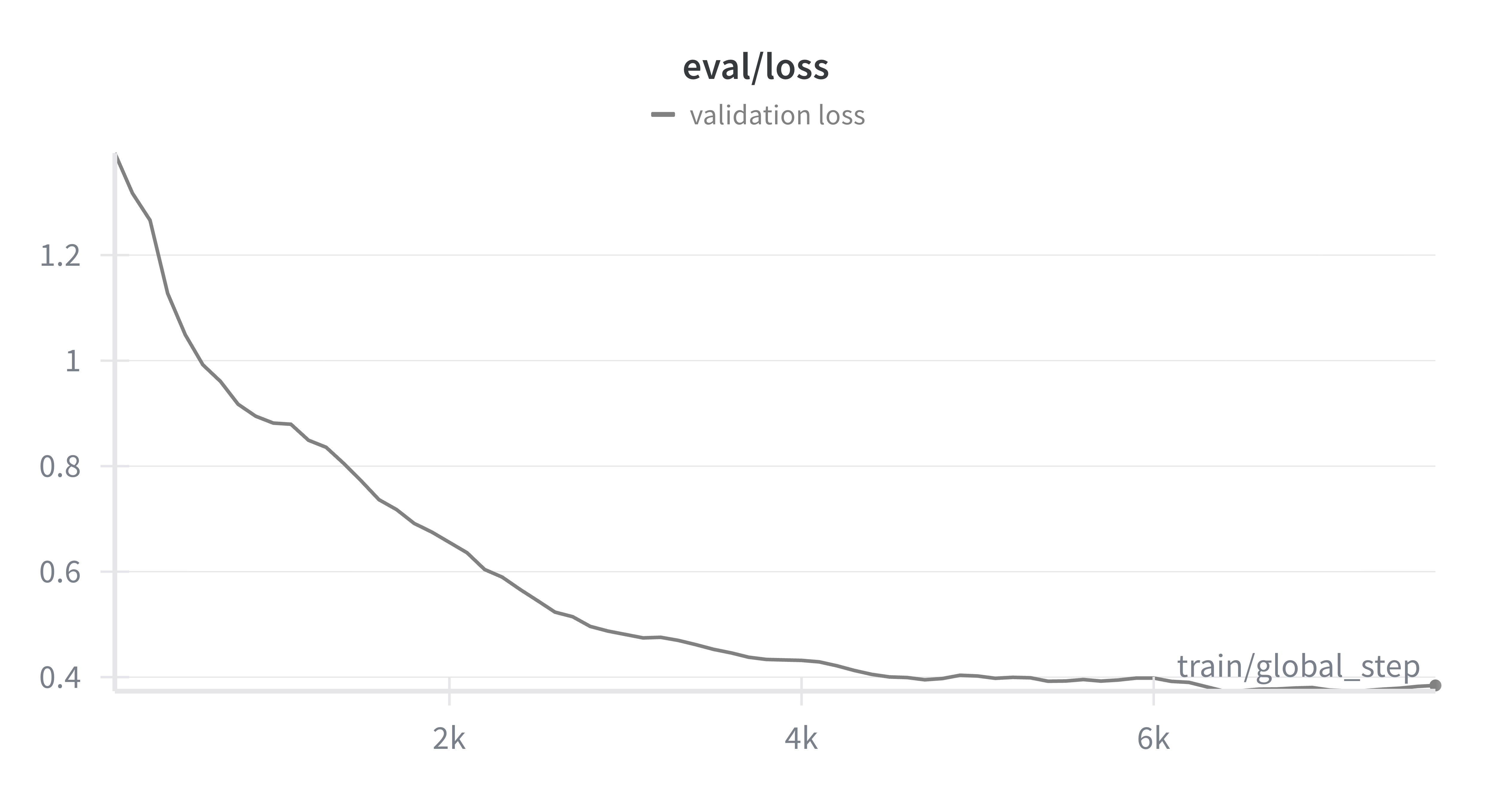
Evaluation loss on real-world validation data
Now when looking at the domain-specific metric, Mean Average Precision (mAP), we see that it improves and then saturates at around mAP ≈ 0.67. This shows that the pipeline works and that synthetic data plus DETR can transfer to this real-world setting, but still below what's usable in a production-ready detector.
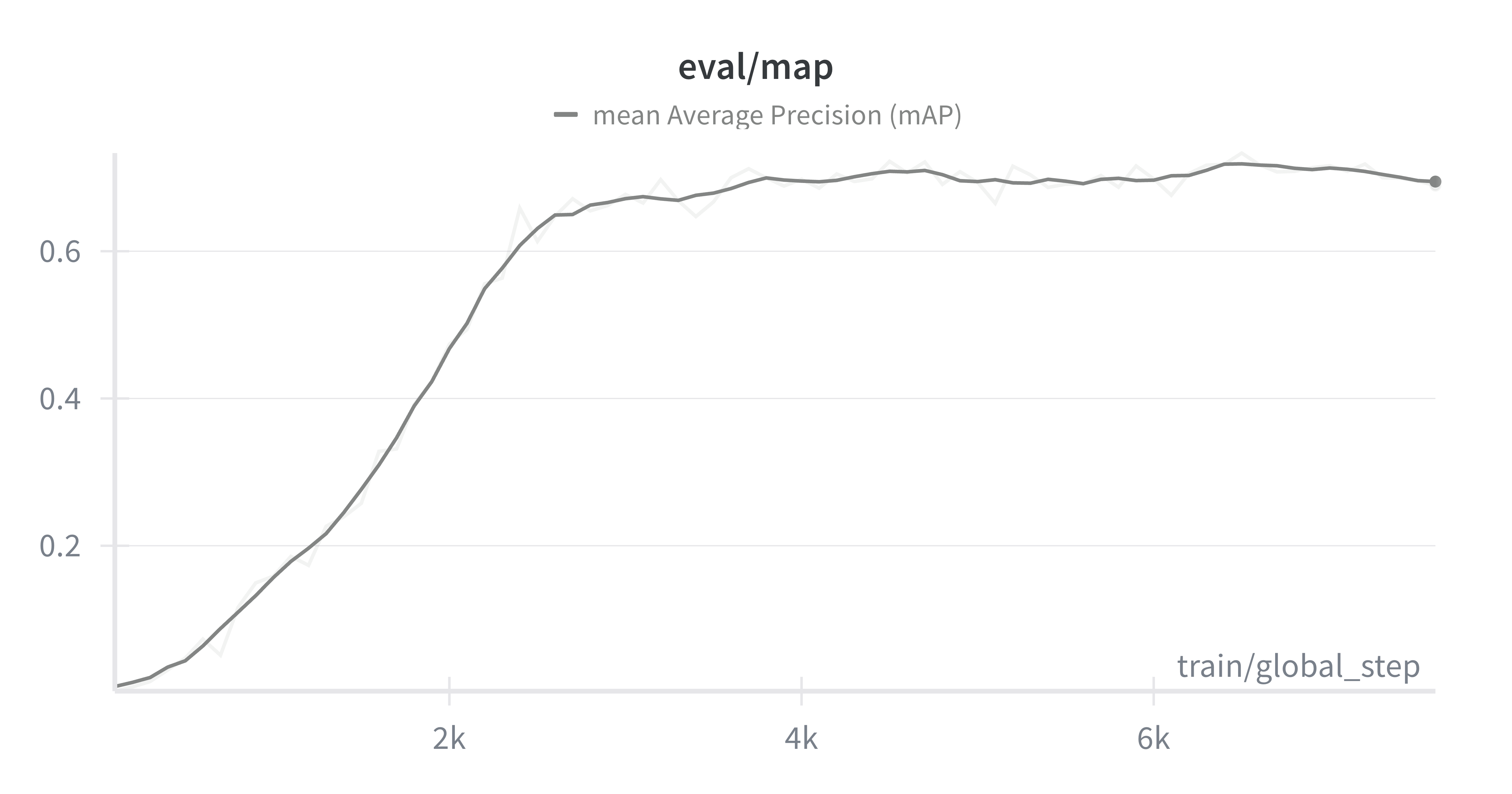
Mean Average Precision (mAP) metric progression during fine-tuning
Qualitatively, the model detects the Minion and the Butter quite well, but struggles with the Toy Cow and the Stapler.

Fine-tuned DETR model detecting objects in the Homebrew dataset
Per-class mAP makes that clear: Toy Cow and Stapler lag behind. That suggests focusing next on (1) upsampling or generating more diverse data for those classes, (2) increasing the variety of poses and contexts for those objects in the synthetic data, or (3) improving their rendering in Blender.
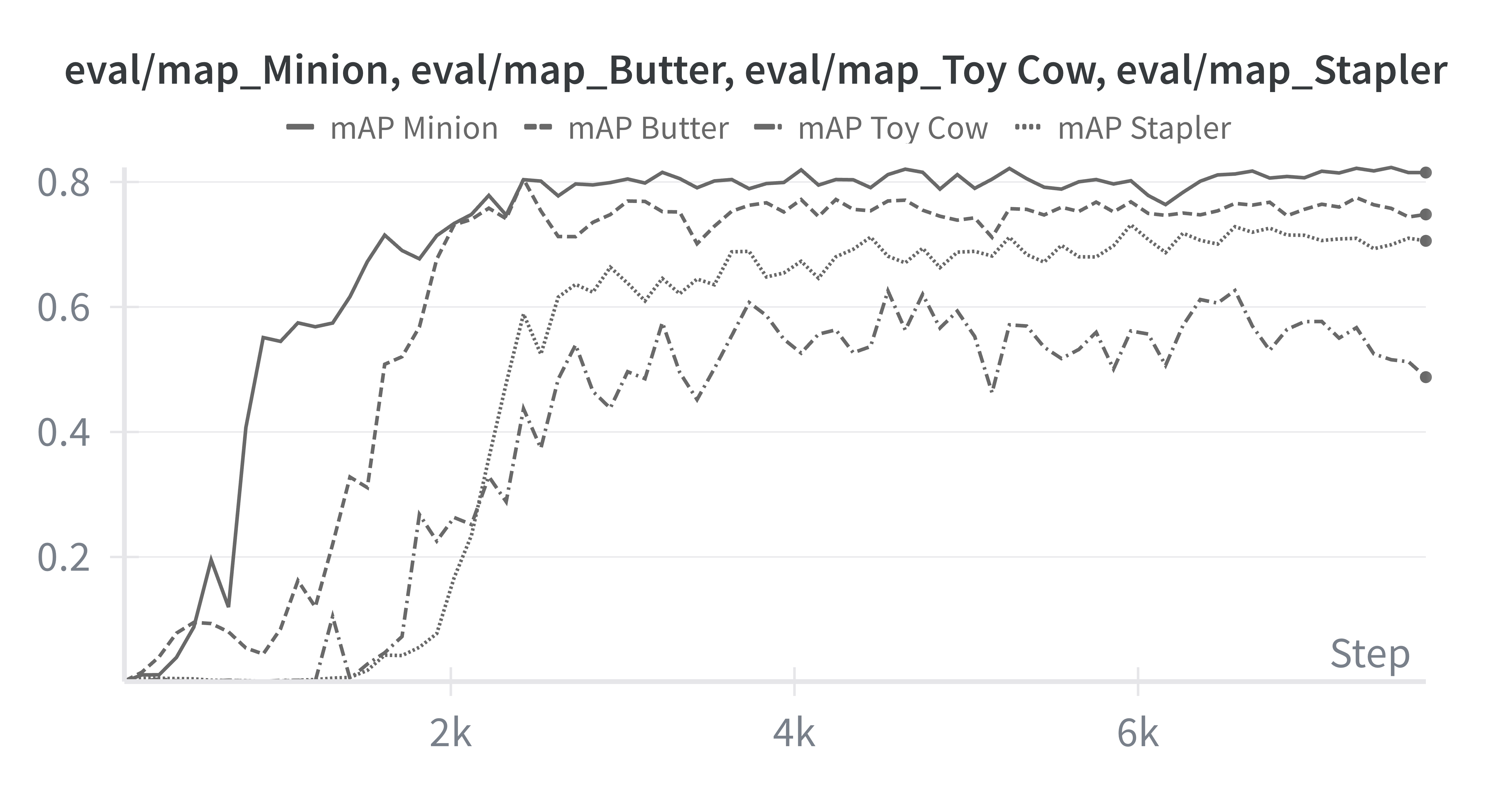
Our trained model's mAP across each of the classes
Conclusions
This blogpost demonstrated went from a concrete real-world object detection task to generating synthetic training data in Blender with sdg-engine, fine-tuning DETR with HuggingFace, and evaluating on the real-world BOP Homebrew validation set.
The model generalizes to the target domain and reaches about mAP ≈ 0.67, with clear headroom via better data balance, diversity, and scene quality. I encourage you to try the full two-part tutorial and to outperform this baseline — and to share what worked for you!
[1] BOP Benchmark – 6D Object Pose Estimation. If you're working on 6D pose estimation, you'll almost certainly run into BOP. It's the go-to benchmark for comparing methods, with well-defined datasets, metrics, and evaluation scripts.
[2] HomebrewedDB (ICCVW 2019). A practical RGB-D dataset for 6D pose estimation, with more realistic, messy scenes (clutter, occlusion, imperfect captures), which makes it a good complement to cleaner benchmarks.